逻辑回归模型原理及Python实现
时间:2024-09-06 09:45:05来源:Lwgzc手游网作者:佚名我要评论 用手机看

扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
核心:线性回归+sigmoid映射。
一、概述
逻辑回归模型(Logistic Regression,LR),由名称上来看,似乎是一个专门用于解决回归问题的模型,事实上,该模型更多地用于解决分类问题,尤其是二分类问题。这并不矛盾,因为逻辑回归直接输出的是一个连续值,我们将其按值的大小进行切分,不足一定范围的作为一个类别,超过一定范围的作为一个类别,这样就实现了对分类问题的解决。概况来说就是,先对数据以线性回归进行拟合,输出值以Sigmoid函数进行映射,映射到0和1之间,最后将S曲线切分上下两个区间作为类别区分的依据。二、算法原理
算法核心是线性回归+sigmoid映射。具体来说,就是对于一个待测样本,以指定的权重和偏置量,计算得到一个输出值,进而将该输出值经过sigmoid进一步计算,映射至0和1之间,大于0.5的作为正类,不足0.5的作为负类。模型原理图示可概括为
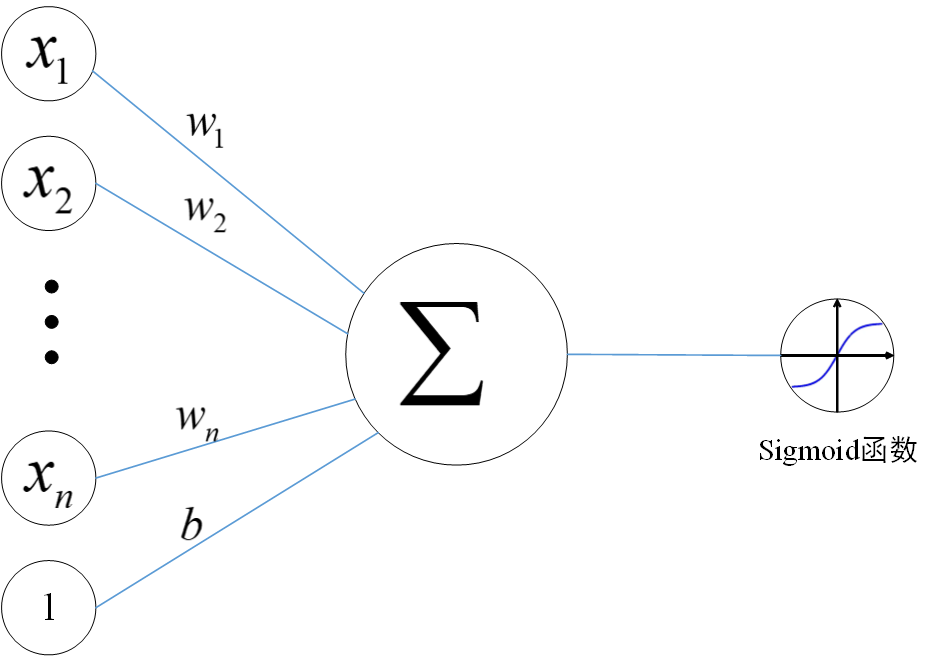
线性回归的表达式可表示为
\(z=w\cdot x+b\)
,sigmoid函数表达式表示为
\(y=\frac{1}{1+e^{-z}}\)
,那么逻辑回归模型的表达式即是
\(y=\frac{1}{1+e^{-(w\cdot x+b)}}\)
。
逻辑回归的分类算法可表示为
逻辑回归模型的训练采用交叉熵损失函数,在优化过程中,计算得到最佳的参数值,表达式如下
三、Python实现
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
## 1.定义数据集
train_x = [
[4.8,3,1.4,0.3],
[5.1,3.8,1.6,0.2],
[4.6,3.2,1.4,0.2],
[5.3,3.7,1.5,0.2],
[5,3.3,1.4,0.2],
[7,3.2,4.7,1.4],
[6.4,3.2,4.5,1.5],
[6.9,3.1,4.9,1.5],
[5.5,2.3,4,1.3],
[6.5,2.8,4.6,1.5]
]
# 训练数据标签
train_y = [
'A',
'A',
'A',
'A',
'A',
'B',
'B',
'B',
'B',
'B'
]
# 测试数据
test_x = [
[3.1,3.5,1.4,0.2],
[4.9,3,1.4,0.2],
[5.1,2.5,3,1.1],
[6.2,3.6,3.4,1.3]
]
# 测试数据标签
test_y = [
'A',
'A',
'B',
'B'
]
train_x = np.array(train_x)
train_y = np.array(train_y)
test_x = np.array(test_x)
test_y = np.array(test_y)
## 2.模型训练
clf_lr = LogisticRegression()
rclf_lr = clf_lr.fit(train_x, train_y)
## 3.数据计算
pre_y = rclf_lr.predict(test_x)
accuracy = metrics.accuracy_score(test_y,pre_y)
print('预测结果为:',pre_y)
print('准确率为:',accuracy)

End.
pdf下载
热门手游下载
 圆梦沉默
圆梦沉默 风味夜市餐厅
风味夜市餐厅 smilemo 手机版
smilemo 手机版 毒液生存菜单版
毒液生存菜单版 麻辣烫大师免广告
麻辣烫大师免广告 隐秘的原罪3 官方下载
隐秘的原罪3 官方下载 植物大战僵尸增强版
植物大战僵尸增强版 樱花高校恋爱生活
樱花高校恋爱生活 开局一仙人 最新版
开局一仙人 最新版 宝可梦漆黑的魅影5.0
宝可梦漆黑的魅影5.0 进化之地 中文版手机
进化之地 中文版手机 放置博物馆恐龙大亨(IDLE Dino Museum)
放置博物馆恐龙大亨(IDLE Dino Museum) smilemo
smilemo 萤火突击 官网免费版
萤火突击 官网免费版
相关文章
- 深入了解Docker环境及Docker Compose的安装步骤
- WebSocket通信问题排查及优化
- GoFrame框架的Docker容器部署指南
- 新手入门 | 搭建 AI 模型开发环境
- OpenCV开发笔记(八十):基于特征点匹配实现全景图片拼接
- C#/.NET/.NET Core技术前沿周刊
- 【解决方案】项目重构之如何使用 MySQL 替换原来的 MongoDB
- 毕业设计中的编程类大作业
- VS Code 代码片段指南: 从基础到高级技巧
- Semantic Kernel/C#:一种通用的Function Calling方法,文末附经测试可用的大模型
- Swahili-text:华中大推出非洲语言场景文本检测和识别数据集 | ICDAR 2024
- 数据库服务器运维的最佳实践指南
热门文章


热门手游推荐
换一批


















- 1
我的钓鱼生活手游
- 2
2048清手游
- 3
继续说不会炸 中文版
- 4
违和感推理游戏
- 5
人类游乐场 安卓免费版
- 6
植物大战僵尸杂交版 手机版直装版
- 7
趣味答题猜谜
- 8
我的世界烦人的村民 安卓版
- 9
海豹馆怪谈 2024最新版
- 10
少女西德妮地下城历险记 免费版
 我的钓鱼生活手游
我的钓鱼生活手游 2048清手游
2048清手游 继续说不会炸 中文版
继续说不会炸 中文版 违和感推理游戏
违和感推理游戏 人类游乐场 安卓免费版
人类游乐场 安卓免费版 植物大战僵尸杂交版 手机版直装版
植物大战僵尸杂交版 手机版直装版 趣味答题猜谜
趣味答题猜谜 我的世界烦人的村民 安卓版
我的世界烦人的村民 安卓版 海豹馆怪谈 2024最新版
海豹馆怪谈 2024最新版 少女西德妮地下城历险记 免费版
少女西德妮地下城历险记 免费版 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 咸鱼大翻身游戏 1.18397 安卓版
咸鱼大翻身游戏 1.18397 安卓版 跨越奔跑大师游戏 0.1 安卓版
跨越奔跑大师游戏 0.1 安卓版 死神之影2游戏 0.42.0 安卓版
死神之影2游戏 0.42.0 安卓版 Escapist游戏 1.1 安卓版
Escapist游戏 1.1 安卓版 烤鱼大师小游戏 1.0.0 手机版
烤鱼大师小游戏 1.0.0 手机版 旋转陀螺多人对战游戏 1.3.1 安卓版
旋转陀螺多人对战游戏 1.3.1 安卓版 地铁跑酷黑白水下城魔改版本 3.9.0 安卓版
地铁跑酷黑白水下城魔改版本 3.9.0 安卓版 加查之花 正版
加查之花 正版